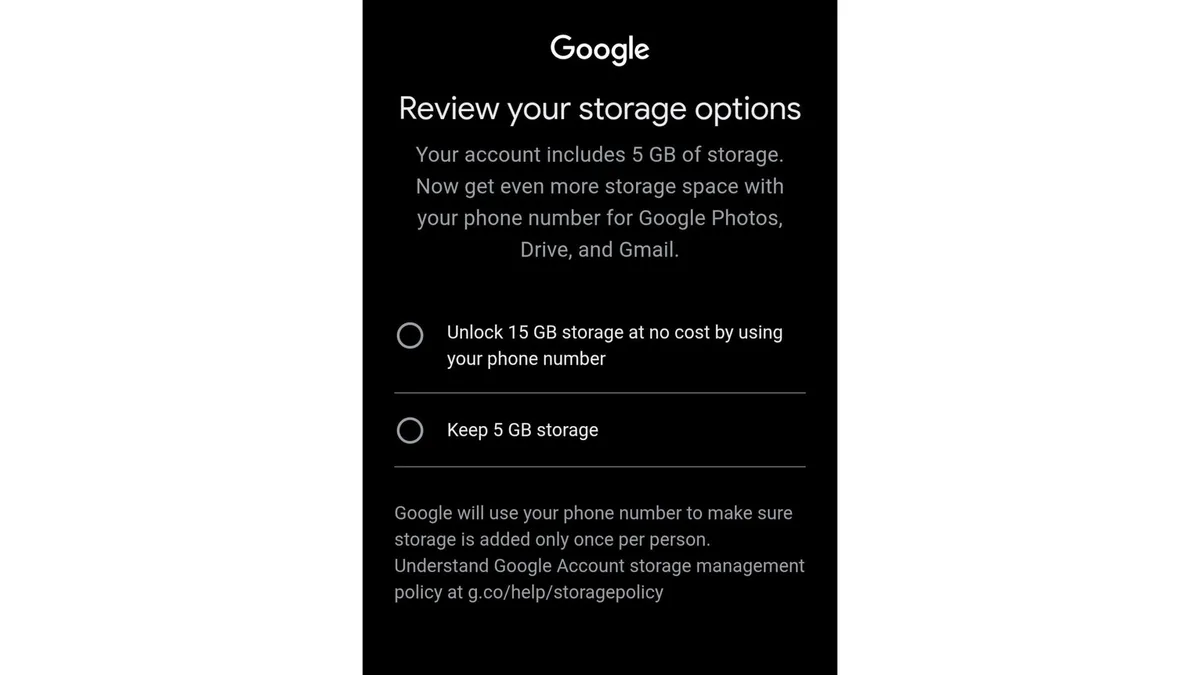
파일 하나 올리려는데 ‘저장 공간 부족’ 알림이 뜬다. 순간 멍해진다. 15GB면 충분하다고 생각했는데, 언제 이렇게 됐지? 고해상도 사진 몇 장, 영상 몇 개, 첨부파일 쌓인 메일함이 조용히 공간을 갉아먹은 것이다. 여기에 구글이 새 계정의 무료 용량을 추가로 줄이는 방향을 테스트 중이라는 소식까지 나왔다. Engadget이 전한 바에 따르면, 구글은 일부 지역에서 휴대폰 번호를 연동하지 않은 신규 계정의 무료 저장 공간을 5GB로 제한하는 실험을 진행 중이다. 무제한으로 쓸 수 있다는 생각은 이미 끝났다. 이제는 전략이 필요하다.
용량이 이렇게 빨리 차는 이유
구글의 15GB는 세 곳이 나눠 쓴다. Gmail, 구글 포토, 구글 드라이브. 하나라도 폭발하면 전체가 막힌다. 2021년 6월 이전에는 구글 포토가 ‘고화질’ 옵션으로 무제한 백업을 제공했다. 지금은 없다. 모든 사진과 영상이 15GB 안으로 들어온다. 스마트폰 원본 사진 한 장이 평균 4~8MB라면, 2,000장만 쌓여도 이미 한계에 다다른다.
서비스 회사 입장도 이해는 간다. 4K 영상, RAW 사진, 대용량 업무 파일 — 우리가 만드는 데이터 규모가 5년 전과 비교 자체가 안 된다. 저장 비용은 올라가는데 무료로 퍼줄 수는 없는 구조다. 결국 유료 전환 유도. 클라우드 업계 전반의 흐름이기도 하다.
내 구글 계정, 뭐가 얼마나 차지하고 있나
막연하게 정리하면 지치고 효율도 없다. drive.google.com/settings/storage에 들어가면 Gmail, 드라이브, 포토 각각 몇 GB씩 쓰는지 막대 그래프로 한눈에 보여준다. 여기서 확인하고 시작하는 게 맞다.
- Gmail: 묵은 뉴스레터, 10MB 넘는 첨부파일, 읽지도 않은 스팸 메일이 조용히 용량을 잠식한다. 검색창에
has:attachment larger:10M을 치면 대용량 메일이 한 번에 걸린다. - 구글 포토: 원본 화질로 백업해온 사진들이 제일 위험하다. 스크린샷, 중복 사진, 흔들린 사진을 주기적으로 비우는 것만으로도 체감이 다르다. 포토 앱 내 ‘제안’ 기능이 흐릿하거나 비슷한 사진을 자동으로 묶어줘서 편하다.
- 구글 드라이브: 내가 올린 파일뿐 아니라, 다른 사람이 공유한 것을 ‘내 드라이브에 추가’한 파일도 용량을 먹는다. 이걸 모르고 쌓아두는 경우가 꽤 많다. 확인해보면 깜짝 놀란다.
실제로 효과 있는 정리 순서
용량 정리는 큰 파일부터가 원칙이다. 드라이브에서 ‘저장용량’ 기준 정렬을 누르면 수십 MB짜리 파일이 위로 올라온다. 묵은 동영상, 예전에 받아뒀던 설치 파일, 압축 파일 — 이것들 몇 개만 지워도 GB 단위가 빠진다.
- 가장 큰 파일 먼저: 드라이브 저장용량 정렬 → 100MB 넘는 것부터 확인. 필요 없으면 바로 삭제.
- 오래된 파일: ‘최종 수정일’ 정렬로 2년 이상 안 열어본 파일을 추린다. 당시엔 중요했어도 지금은 아닌 것들이 생각보다 많다.
- 중복 파일: 드라이브 자체에 중복 감지 기능은 없다. MultCloud 같은 서드파티 툴을 쓰거나, 직접 폴더별로 훑는 수밖에 없다. 귀찮지만 어쩔 수 없다.
- Gmail 대용량 메일:
has:attachment larger:10M검색 후 불필요한 것 삭제. 메일함 휴지통도 따로 비워야 한다는 걸 잊기 쉽다. - 구글 포토 스크린샷·중복: 제안 기능 + 앨범 단위로 훑기. 이거 한 번 하면 1~2GB 뽑아내는 경우도 많다.
하나 빠뜨리기 쉬운 것. 삭제 후 휴지통을 비워야 실제 용량이 확보된다. 드라이브, 포토, Gmail 각각 휴지통이 따로 있다. 세 곳 다 비워야 숫자가 줄어든다.
무료 클라우드 여러 개 조합하면 꽤 쓸 만하다
하나만 쓰면 한계가 있다. 용도별로 나눠 쓰면 총합이 늘어난다. 현재 주요 무료 클라우드 용량을 보면:
- 네이버 MYBOX: 30GB. 국내 서비스라 접속 안정성이 좋다. 개인 사진, 가족 사진 보관용으로 나쁘지 않다. 실제로 개인 사진은 여기에 몰아두고 있다.
- Microsoft OneDrive: 5GB. 작아 보이지만 MS 오피스 파일과 연동이 매끄럽다. Microsoft 365 구독자라면 1TB가 딸려온다 — 이 경우엔 굳이 다른 서비스를 찾을 이유가 없다.
- Dropbox: 2GB로 가장 작다. 대신 공유와 협업 기능이 탄탄해서 팀 프로젝트 특정 폴더 하나 관리하는 용도로는 유용하다. 추천인 이벤트로 추가 용량도 생긴다.
- Mega: 20GB. 암호화 기능이 강해서 민감한 파일 보관에 어울린다. 보안이 신경 쓰인다면 선택지가 된다.
정리하면 업무 문서는 OneDrive, 개인 사진은 MYBOX, 공유 작업은 구글 드라이브로 분산하는 식이다. 한 서비스가 꽉 차도 나머지가 있으니 심리적 여유가 생긴다. 앱이 늘어나는 단점은 있다. 이건 솔직히 좀 귀찮기는 하다.
유료 플랜, 살 타이밍이 언제인가
아무리 정리해도 알림이 계속 뜬다면, 그냥 유료로 가는 게 낫다. 시간과 노력의 기회비용을 생각하면 월 몇 천원이 오히려 저렴할 수 있다. 판단 기준 몇 가지:
- 정리해도 계속 부족하다: 데이터 자체가 그만큼 많다는 뜻이다. 구글 원(Google One) 기준으로 100GB가 월 2,900원, 200GB가 월 3,900원 선이다. 하루 커피 한 잔보다 싸다.
- 중요한 파일이 많다: 유료 플랜은 보안 기능과 서비스 안정성이 더 낫다. 업무 자료나 소중한 사진을 무료 계정에만 의존하는 건 솔직히 불안하다.
- 가족과 함께 쓴다: 구글 원이나 애플 iCloud+는 가족 공유 플랜을 제공한다. 한 명이 결제하면 최대 5명이 나눠 쓴다. 각자 따로 구독하는 것보다 훨씬 경제적이다. 구글 원 가족 공유로 바꾸고 나서 사진 백업 걱정이 사라졌다는 사람이 많다.
- 이미 다른 구독을 하고 있다: Microsoft 365나 Apple One을 쓴다면 대용량 클라우드가 이미 포함돼 있다. 중복 구독 전에 먼저 확인하라. 놓치고 있는 경우가 꽤 된다.
유료 플랜은 단순한 저장 공간을 넘어, 강화된 보안과 고객 지원, 그리고 ‘데이터 날릴 위험 감소’라는 가치를 제공한다. 월 구독료가 아깝게 느껴질 수 있지만, 디지털 자산의 무게를 생각하면 합리적인 선택이다.
로컬 백업도 병행해야 하는 이유
클라우드만 믿으면 안 된다. 서버 장애, 계정 해킹, 정책 변경 — 어느 날 갑자기 접근이 막힐 수도 있다. 데이터 보존의 기본인 3-2-1 원칙이 있다. 3개 사본, 2가지 미디어, 1개 오프사이트 보관이다. 개인도 이 방향으로 가는 게 맞다.
- 외장하드/SSD: 접근성 좋고 용량 대비 가격도 많이 내려갔다. 사진·영상 원본은 외장하드에 두고, 클라우드엔 문서와 자주 쓰는 파일 위주로 나눈다.
- NAS(Network Attached Storage): 초기 비용이 들지만 장기적으로 제일 강력하다. 집 안 모든 기기에서 접근되고, RAID 구성으로 디스크 하나가 나가도 데이터가 살아있다. 사진이 수만 장 넘어가면 진지하게 고려할 만하다.
- 정기 동기화: 로컬과 클라우드를 주기적으로 맞춰줘야 한다. 어느 쪽에 문제가 생겨도 복구선이 남아있도록 대비하는 것이 핵심이다.
클라우드는 편하다. 언제 어디서나 접근되고 공유도 쉽다. 외장하드는 들고 다녀야 한다. 이 둘의 역할이 다르다. 둘 다 쓰는 게 답이다.
자주 묻는 것들, 짧게 정리
- 구글 포토 무제한 백업, 지금도 되나?
안 된다. 2021년 6월 1일부로 종료됐다. 이후 저장되는 모든 사진·영상은 15GB 안에 들어간다. 그 이전에 올린 사진은 용량에 잡히지 않는다. - 새 계정 만들 때 휴대폰 번호 연동이 필수가 되나?
아직은 아니다. 구글이 특정 지역에서 테스트 중인 단계다. 연동 안 하면 무료 용량이 5GB로 제한될 수 있다는 내용인데, 정식 정책으로 굳어지면 이야기가 달라진다. 지켜봐야 한다. - 클라우드 간 파일 이동, 가장 빠른 방법은?
직접 다운로드 후 재업로드가 가장 확실하다. 느리다는 게 단점. MultCloud 같은 서비스를 쓰면 클라우드 간 직접 전송이 돼서 로컬 저장 없이 바로 옮겨진다. PC에 각 서비스 동기화 클라이언트를 깔고 로컬에서 이동하는 방법도 있다.
출처: Engadget










