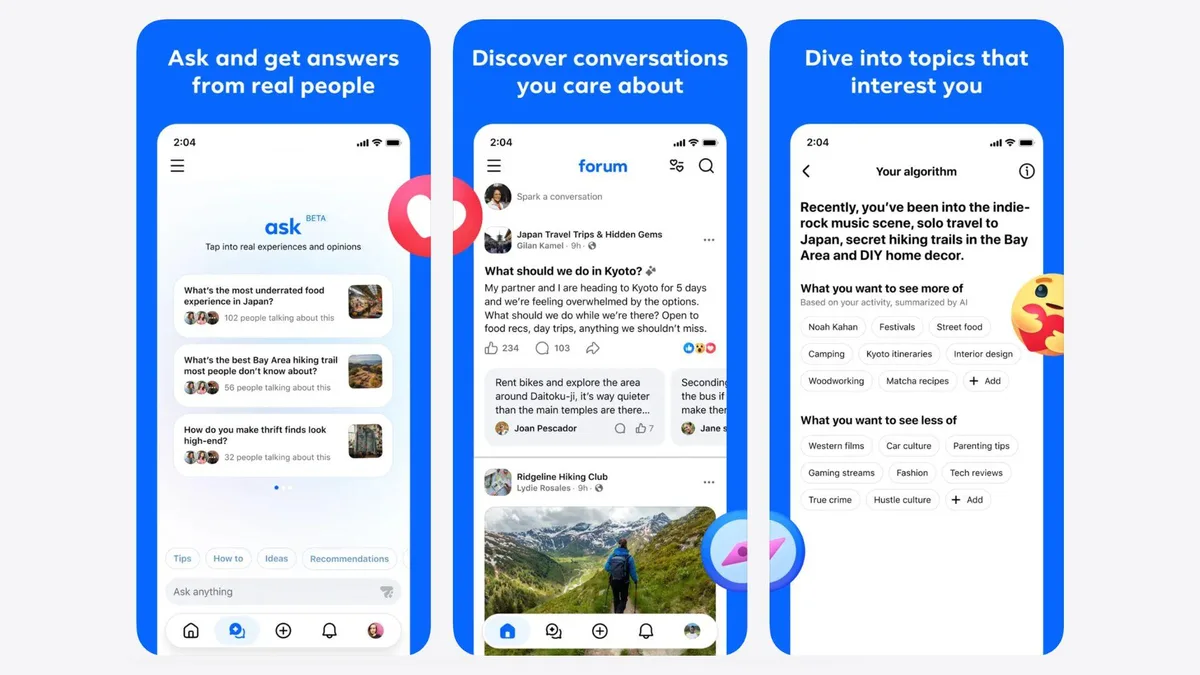
구글 검색창에 ‘reddit’을 붙여서 검색해본 적 있다면, 메타가 만든 ‘포럼(Forum)’ 앱이 노리는 지점이 뭔지 바로 감이 올 거다. 아이폰 전용으로 출시된 이 앱, 한마디로 페이스북 그룹에 AI 챗봇을 얹은 버전이다. 레딧처럼 특정 관심사 중심으로 깊이 파고들 수 있고, 거기에 AI가 질문에 답하고 긴 토론을 요약해준다. 2017년에 ‘페이스북 그룹스(Facebook Groups)’ 앱을 접었던 메타가 다시 같은 판에 뛰어든 건데, 이번엔 무기가 다르다.
메타 ‘포럼’ 앱, 뭐가 다른가
The Verge 보도를 보면 AI가 하는 일이 꽤 구체적이다. 그룹 내 질문에 직접 답하고, 수백 개 댓글로 이어진 토론을 몇 줄로 요약하고, 새로운 토론 주제까지 제안한다. 단순 키워드 검색이 아니라 그룹 맥락을 이해하는 AI라는 게 포인트다. 예를 들면 등산 커뮤니티에서 초보 코스를 물어보면 AI가 관련 게시글들을 뒤져서 바로 요약본을 내놓는 식이다.
기존 페이스북 그룹과 가장 큰 차이는 메인 피드에서 분리됐다는 점이다. 지인들의 근황, 광고, 추천 게시물이 뒤섞인 페이스북 피드에서 벗어나 관심사 하나에만 집중하는 공간을 따로 뺀 것. 이게 레딧(Reddit)이 10년 넘게 버텨온 이유이기도 하고, 페이스북 그룹이 항상 아쉬웠던 지점이기도 하다.
레딧+구글 AI 오버뷰+페이스북 그룹, 한 앱에 다 넣으면?
포럼 앱의 포지셔닝이 흥미롭다. 레딧 특유의 주제별 깊이, 구글의 ‘AI 오버뷰(AI Overview)’ 같은 즉각적인 답변, 페이스북 그룹의 커뮤니티 관리 기능—이 세 가지를 한데 모은 구조다. 수백 개의 게시물을 일일이 뒤지지 않아도 된다. AI가 그룹 내 맥락을 파악해 필요한 정보를 바로 꺼내준다.
문제는 이게 좋은 것만 모아놨다가 될지, 어중간한 것들의 합산에 그칠지다. 레딧을 오래 써본 사람은 안다. 그 플랫폼의 힘은 기능이 아니라 오랫동안 쌓인 사람들과 문화에서 나온다는 걸. 메타가 AI를 앞세워도 그 부분을 단기에 따라잡기는 쉽지 않다. 신규 사용자 입장에서는 다르다. 커뮤니티에 처음 들어갔는데 AI가 핵심 FAQ를 정리해주고 수년 치 논쟁을 맥락 있게 요약해준다면—진입 장벽이 꽤 낮아지는 경험이다. 이 부분에서 메타는 기존 레딧 충성 유저보다 새로운 층을 공략할 여지가 있다.
국내 시장, 직접 충격보다 간접 자극
국내는 네이버 카페, 밴드, 카카오톡 오픈채팅이 워낙 깊이 박혀 있다. 아이폰 전용 앱으로 시작한다는 것도 걸린다. 국내 스마트폰 시장에서 아이폰 점유율이 30%대 초반인 걸 감안하면, 시작부터 타깃 모수가 제한적이다.
그렇다고 무시하기엔 이르다. 서구 시장에서 이 앱이 자리를 잡는다면, 네이버 카페나 밴드가 AI 기반 커뮤니티 기능을 서둘러 도입할 명분이 생긴다. 카카오도 마찬가지다. 메타 ‘포럼’이 국내 시장을 직접 뚫는다기보다, 국내 플랫폼들을 움직이는 촉매 역할을 할 가능성이 더 높다. 결국 어느 플랫폼이 이기든, AI가 녹아든 커뮤니티 경험을 더 빨리 만나게 되는 셈이다.
출처: The Verge